
首先声明,本文非严谨学术论文,无数据分析,无实例支撑,基本只有假设,尤其后半段,包括那张图。目的只是素描一个粗糙的想法,因为,人老了,不记下来就会忘掉。
言归正传。通常生产率(Productivity)可以定义为单位时间内生产的产品数量。在软件开发领域“产品数量”难以找到像螺钉、纽扣一般明确的计件单位,所以软件生产率多以代码行或功能点的数量进行计算。而功能点的定义通常又比较含糊,不同软件产品、不同团队对于功能点的定义都不尽相同。所以代码行几乎是大部分软件企业衡量生产率的唯一标准:Productivity=LOC(Line of Code)/Effort。对这个定义,有两种解读:一,相同时间内(让我们暂且归一化resource,所以时间就是Effort)写的代码行越多则生产率越高;二,完成相同代码行花的时间越少则生产率越高。第二种解读可以理解为编程高手、熟手,基本没错。第一种解读却隐含了另外一个没有明说的假设条件:相同的代码质量。而这个假设条件非常重要,否则,哪怕能够实现同样的功能,我也可以堆砌出一大堆没用的代码。注意这些代码并不是“废品”(“废品”就是bug了),而是“低效”的代码。
这又不得不谈到代码的“效率”问题。那么是否完成相同功能、没有bug的代码,行数越多就“效率”越高呢?让我们先分解一下这个“效率”。我理解代码的“效率”应该包含三个方面:一,代码的片段运行效率,比如算法的选择,内存利用,I/O操作等等;二,代码的整体结构效率,比如函数的定义,头文件的选取,软件架构设计,设计模式的运用等等;三,代码的维护效率,主要指代码的可读性,别人是否很容易接手你的代码。
代码的片段运行效率,事实上跟代码行的多少没有太直接的关系。因为算法的优劣并不等价于代码的多寡。代码的多寡也不能决定内存、寄存器、堆栈、I/O是否有效利用。有时候过于精简的代码反而耗费更长的机器时间。当然过于冗长的代码是一定会降低运行效率的。我无法找到一个准确的曲线来表示代码行和运行效率的关系,也许每个软件都有不同的曲线,也许压根就无法用简单单变量函数表示出来。但大体上,应该还是个概率分布如泊松分布之类的。对于代码的整体结构效率,大体还是有原则可循的,过于精简的结构和过于冗长的结构都会降低程序效率,所以,这是否意味着它还是一个类似泊松分布呢?而对于代码的可维护性,相信大多数程序员都深有体会,一行代码完成过多功能只能让读者不解,而为了某些目的弃简就繁的写法也会让读者头晕。呃,所以,貌似这还是一个类似泊松分布。我当然还是无法确定这三个分解因素在构成“有效”代码时的权重,所以,那就还是假设一条综合泊松曲线得了,如下图黑线所示: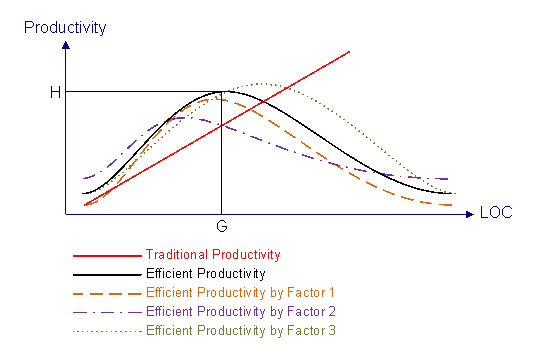 这就明显了,随着代码行的增加,总会有那么个时候软件的效率开始降低从而我们所希望衡量的有效生产率开始降低。其实想个极端的例子:A同学完成一个功能用了一整天,但他这一整天中其实只写了50行代码,但算法恰当,逻辑清晰,结构合理,可读性强;B同学也用一天时间完成同样功能,但洋洋洒洒写了500行——因为重复了若干遍本可以抽象出来的函数。B同学的生产率是A同学的10倍,但B同学写的却是烂程序(当然,也许B同学也不是故意的)。如果简单以这样的生产率作为激励标准,那么显然对于A同学是不公平的。而我们希望更多的像A同学这样的程序员。
这就明显了,随着代码行的增加,总会有那么个时候软件的效率开始降低从而我们所希望衡量的有效生产率开始降低。其实想个极端的例子:A同学完成一个功能用了一整天,但他这一整天中其实只写了50行代码,但算法恰当,逻辑清晰,结构合理,可读性强;B同学也用一天时间完成同样功能,但洋洋洒洒写了500行——因为重复了若干遍本可以抽象出来的函数。B同学的生产率是A同学的10倍,但B同学写的却是烂程序(当然,也许B同学也不是故意的)。如果简单以这样的生产率作为激励标准,那么显然对于A同学是不公平的。而我们希望更多的像A同学这样的程序员。
可惜的是,那个代表最佳代码行的G点真的很难找到啊。
