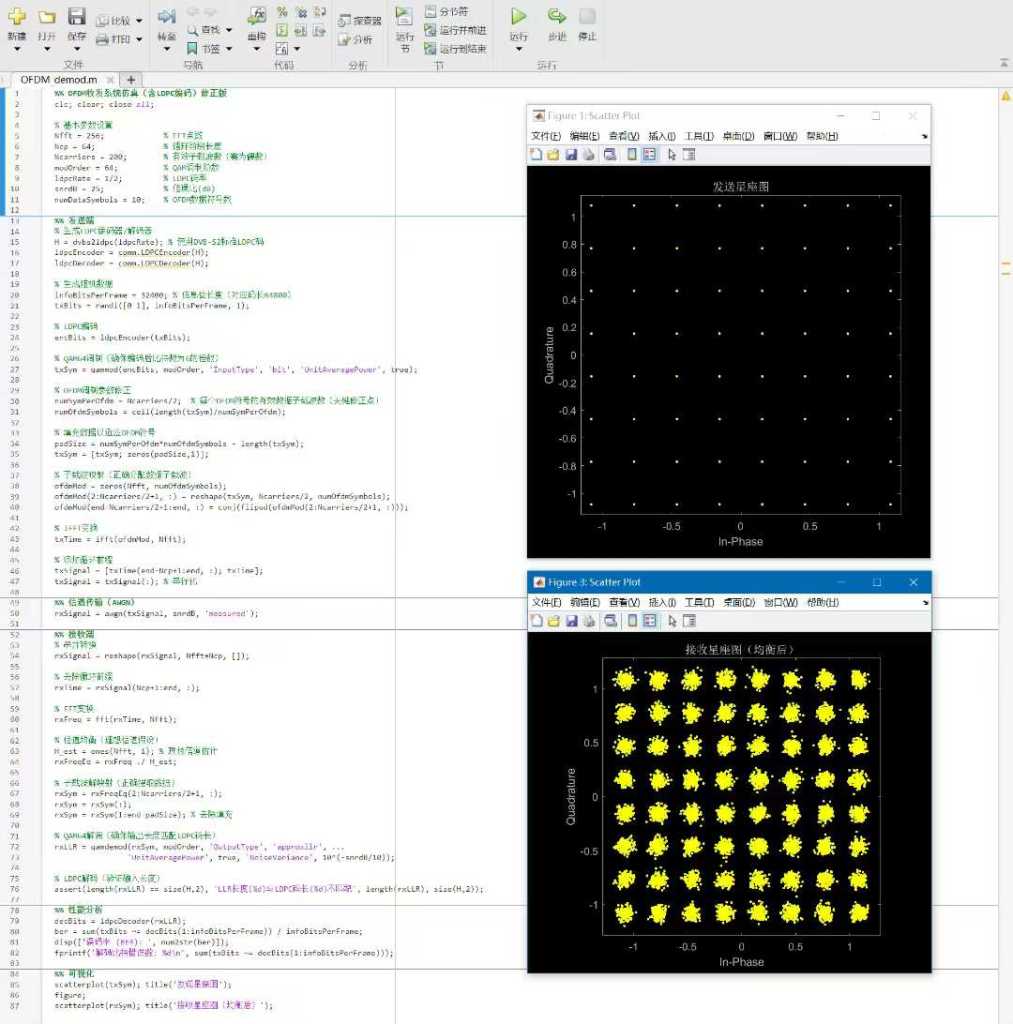
这个春节寒假就是个疯狂的AI假期。Claude Opus 4.6、GPT 5.3 Codex,GLM 5等国内外新一代大模型相继发布,让半个程序员的我陷入狂喜之中,每天2点才能睡觉,有时间就折腾他们,好多想干的事终于在AI进化到今天的智能后可以干了。
让GPT 5.4自己去爬文件夹,对假期中的AI编程做个总结,它花了2分钟干这事,最后生成个word文档,内容如下:
Programs 目录程序汇总报告
目录: D:\BaiduSyncdisk\Denny\Programs
统计说明
本报告按“一个程序 = Programs 下一个一级子目录”整理,共 12 个程序目录。
文件数统计排除了虚拟环境、缓存、打包产物和 IDE 元数据目录,例如 .git、.venv、venv、__pycache__、build、dist、downloads、output、outputs、results、video_frames 等。
代码总行数仅统计源码/脚本文件,例如 .py、.ipynb(仅代码单元)、.cpp/.c、.ps1、.html 等;Markdown、JSON、图片、模型和数据文件不计入代码行数。
用途说明优先依据 README、说明文档和主脚本名称/内容推断;无法确认的目录会明确标注不确定性。
总体结论
当前全部程序合计文件数为 609,代码总行数为 26092。
按代码总行数看,规模最大的 3 个目录是 XL_PSS(6373 行)、DVS_codes(3708 行)和 Robot_AI(3474 行)。
按文件数看,数量最多的 3 个目录是 CV_face(258 个)、CV_simple(149 个)和 ResNet50(67 个)。
这些项目大致可以分为 4 类:计算机视觉/深度学习、信号与通信分析、机器人/自动化、以及可视化仿真工具。
其中 Robot_AI、CV_face、CV_simple 的文件数仍受资料包或样本图片影响,不能简单等同于软件复杂度。
程序总表
程序目录 主要用途 文件数 代码总行数 备注 Boids_sim_py 基于 Craig Reynolds Boids 模型的鸟群/群体行为仿真,目录中保留了多个由不同模型生成的实现版本,适合做算法演示和实现对比。 12 3127 以 Pygame 实时动画为主。 CV_face 人脸识别完整流程项目,包含摄像头测试、数据采集、数据集切分、模型训练和实时识别。 258 508 文件数主要由样本图片组成。 CV_simple 空间种植/植物状态视觉识别项目,用于识别植物健康状态和生长阶段,并支持实时摄像头检测。 149 915 目录中包含训练样本和两个识别模型。 DVS_codes DVS 事件相机数据处理与可视化工具集,重点是 EVT3/RAW/HDF5 数据解析、多版本播放器和 Metavision SDK 集成。 40 3708 包含多版 viewer、示例数据和格式参考图。 DVS_trigger_RGB 用于浏览和下载远程服务器上 DVS 触发的 RGB 照片的桌面工具,带登录、轮询、目录解析和 GUI 查看能力。 9 575 主体代码集中在单个 Python 脚本。 LEO_TDOA_Simulation LEO 卫星 TDOA 定位仿真,涉及信号检测、测向、链路预算、GDOP 和 Monte Carlo 分析,并提供 GUI。 7 2274 README 描述完整,定位明确。 Phased-array-antenna-pattern 相控阵天线方向图 GUI 仿真程序,用于波束扫描、2D/3D 方向图显示和主瓣/旁瓣/波束宽度分析。 3 393 体量较小但目标单一清晰。 ResNet50 基于 TensorFlow/Keras 的 ResNet50 计算机视觉学习系统,覆盖数据处理、训练、推理和 Notebook 教学示例。 67 2309 同时包含脚本和教学型 Notebook。 Robot_AI 树莓派小车/机器人控制系统,支持 Web 端远程控制、避障、视频监控和自动/手动模式切换。 29 3474 参考资料减少后,统计更接近核心项目规模,但仍混有硬件资料和附件。 SNN_learning 脉冲神经网络(SNN)演示程序,展示网络结构、脉冲栅格图、膜电位变化和可视化分析。 2 626 更像单文件教学演示。 URL_monitor WiFi 监听模式下的 URL/DNS 查询监控工具,可按关键字或域名告警,并支持日志、桌面通知和邮件提醒。 4 1810 单脚本项目,但逻辑较完整。 XL_PSS 针对星链上行 IQ/PCM 数据的突发检测、OFDM 参数估计、CP/PSS 提取和相位分析工具链。 29 6373 分析脚本较多,项目偏研究/信号处理。
逐目录备注
Boids_sim_py
用途: 基于 Craig Reynolds Boids 模型的鸟群/群体行为仿真,目录中保留了多个由不同模型生成的实现版本,适合做算法演示和实现对比。
统计: 文件数 12,代码总行数 3127,代码文件数 11。
主要文件类型: .py x 11、.md x 1
备注: 以 Pygame 实时动画为主。
CV_face
用途: 人脸识别完整流程项目,包含摄像头测试、数据采集、数据集切分、模型训练和实时识别。
统计: 文件数 258,代码总行数 508,代码文件数 5。
主要文件类型: .jpg x 250、.py x 5、.h5 x 1、.json x 1、.md x 1
备注: 文件数主要由样本图片组成。
CV_simple
用途: 空间种植/植物状态视觉识别项目,用于识别植物健康状态和生长阶段,并支持实时摄像头检测。
统计: 文件数 149,代码总行数 915,代码文件数 6。
主要文件类型: .jpg x 138、.py x 6、.h5 x 2、.cfg x 1、.json x 1、.md x 1
备注: 目录中包含训练样本和两个识别模型。
DVS_codes
用途: DVS 事件相机数据处理与可视化工具集,重点是 EVT3/RAW/HDF5 数据解析、多版本播放器和 Metavision SDK 集成。
统计: 文件数 40,代码总行数 3708,代码文件数 11。
主要文件类型: .jpeg x 14、.py x 11、.raw x 6、.tmp_index x 6、.spec x 2、.xml x 1
备注: 包含多版 viewer、示例数据和格式参考图。
DVS_trigger_RGB
用途: 用于浏览和下载远程服务器上 DVS 触发的 RGB 照片的桌面工具,带登录、轮询、目录解析和 GUI 查看能力。
统计: 文件数 9,代码总行数 575,代码文件数 2。
主要文件类型: .txt x 2、.docx x 1、.html x 1、.json x 1、.md x 1、.png x 1
备注: 主体代码集中在单个 Python 脚本。
LEO_TDOA_Simulation
用途: LEO 卫星 TDOA 定位仿真,涉及信号检测、测向、链路预算、GDOP 和 Monte Carlo 分析,并提供 GUI。
统计: 文件数 7,代码总行数 2274,代码文件数 3。
主要文件类型: .py x 3、.md x 1、.spec x 1、.txt x 1、[no ext] x 1
备注: README 描述完整,定位明确。
Phased-array-antenna-pattern
用途: 相控阵天线方向图 GUI 仿真程序,用于波束扫描、2D/3D 方向图显示和主瓣/旁瓣/波束宽度分析。
统计: 文件数 3,代码总行数 393,代码文件数 2。
主要文件类型: .md x 1、.ps1 x 1、.py x 1
备注: 体量较小但目标单一清晰。
ResNet50
用途: 基于 TensorFlow/Keras 的 ResNet50 计算机视觉学习系统,覆盖数据处理、训练、推理和 Notebook 教学示例。
统计: 文件数 67,代码总行数 2309,代码文件数 24。
主要文件类型: .jpg x 22、.py x 18、.png x 10、.ipynb x 6、.md x 6、[no ext] x 3
备注: 同时包含脚本和教学型 Notebook。
Robot_AI
用途: 树莓派小车/机器人控制系统,支持 Web 端远程控制、避障、视频监控和自动/手动模式切换。
统计: 文件数 29,代码总行数 3474,代码文件数 17。
主要文件类型: .py x 13、.md x 6、.yaml x 2、.css x 1、.html x 1、.js x 1
备注: 参考资料减少后,统计更接近核心项目规模,但仍混有硬件资料和附件。
SNN_learning
用途: 脉冲神经网络(SNN)演示程序,展示网络结构、脉冲栅格图、膜电位变化和可视化分析。
统计: 文件数 2,代码总行数 626,代码文件数 1。
主要文件类型: .png x 1、.py x 1
备注: 更像单文件教学演示。
URL_monitor
用途: WiFi 监听模式下的 URL/DNS 查询监控工具,可按关键字或域名告警,并支持日志、桌面通知和邮件提醒。
统计: 文件数 4,代码总行数 1810,代码文件数 1。
主要文件类型: .json x 1、.log x 1、.py x 1、.txt x 1
备注: 单脚本项目,但逻辑较完整。
XL_PSS
用途: 针对星链上行 IQ/PCM 数据的突发检测、OFDM 参数估计、CP/PSS 提取和相位分析工具链。
统计: 文件数 29,代码总行数 6373,代码文件数 24。
主要文件类型: .py x 24、.docx x 1、.md x 1、.mp4 x 1、.pcm x 1、.pdf x 1
备注: 分析脚本较多,项目偏研究/信号处理。
建议
如果后续要做更精确的软件资产盘点,建议把“源码”“数据”“模型”“参考资料”“打包产物”拆开分别统计。
Robot_AI 适合再拆分“核心 Python 应用”和“随附硬件资料/示例代码”两部分,否则其规模统计仍会被附件放大。
如果你后面还会继续删减数据集或参考资料,建议固定一份统计口径,便于做前后版本对比。
够强吧?GPT 5.4的能力不仅仅在一流的编程,它实际上自带的skills和MCP能力已经完全可以不用不安全的OpenClaw了。当然,这花费我160/月,但绝对值得。
这些程序中花时间最多的是Robot_AI,树莓派智能小车程序,而且还花了我1400银子买树莓派、小车、电机、超声波传感器、红外传感器、电阻、排线等等。现在,这台小车能自动避障行驶,能看到我进行跟随,丢失我转圈寻找,我远离它靠近,我靠近它远离,特别有意思。下一步,还想加上语音控制,不知道树莓派5的心智是否能支撑?当然这个问题也可以先寻求AI的帮助。
视频在这里:树莓派5智能避障、跟随人脸小车,全AI架构设计、硬件设计、原材料采购推荐、组装指导、软件算法、软件编码。-其他-高清完整正版视频在线观看-优酷
最后谈谈AI编程对软件工程师的影响。这个话题似乎已经被谈滥了,我只说我自身的感受。
假期前有员工离职,留下一个硬件设备里嵌入式软件中的bug。大家发现这个bug已经有两三年了,是个产品中的老问题,但因为它是偶发性,很难复现,所以很难修复,就没人管它了。但假期前集中测试设备,遇到了两三次,这对即将交付的产品来说是致命的,用户肯定无法接受,到时候派人去现场调试成本就太大了。但嵌入式工程师已经离职,而且最近天天加班到晚上10点,周末也不休息,根本没时间回来弄。
那就让AI帮忙吧。
进到他留下的电脑,开虚拟机,终端安装Opencode CLI,打开VS Code,装上Opencode插件,打开他的app工程目录,告诉Opencode这个代码的目的、功能、现在的问题表现、可能的调试方向,然后它就开始吭哧吭哧读代码,理思路,最后给我指出代码可能存在的问题,问我是否允许它动手改。那就改吧。几分钟后它说改好了,也自动编译了,让我把二进制文件拷贝进设备验证。我欢天喜地把二进制拷进设备,可以运行,但偶发问题没法短时间验证,反而发现它影响了设备其它功能,我晕!告诉它问题,它认错。这次它开始完整研究代码,找出它的改动为啥影响了其它功能,然后又出一个版本让我测试。就这样它改一版,我测一版,我就是它的测试工程师。一天下来,最后所有功能都能正常执行了,但这个偶发问题是否真的被修复,还需要时间验证。【三月补充:经过2-3个星期的观察,偶发性问题好像确实没有再发生了。顺手还让它修复了另外一两个小问题。所以,我这个半拉子工程师让AI搞定了一个团队两三年没搞定的很隐蔽的偶发性问题!服不服?】
我自己总结AI对软件开发人员的影响:
1,不用AI的工程师是注定被淘汰的第一波人;
AI对普通人、龙虾对普通人、龙虾对程序员的作用是什么?下个月再聊吧,困。